87% of AI-Generated Pull Requests Ship Security Vulnerabilities
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
 esc to close
esc to closeDryRun Security released their Agentic Coding Security Report last week1. The headline number: 87% of AI-generated pull requests introduced at least one security vulnerability.
That's 26 out of 30 PRs. 143 total vulnerabilities across 38 scans. Zero fully secure applications produced by any agent.
Those numbers deserve a closer look.
The methodology
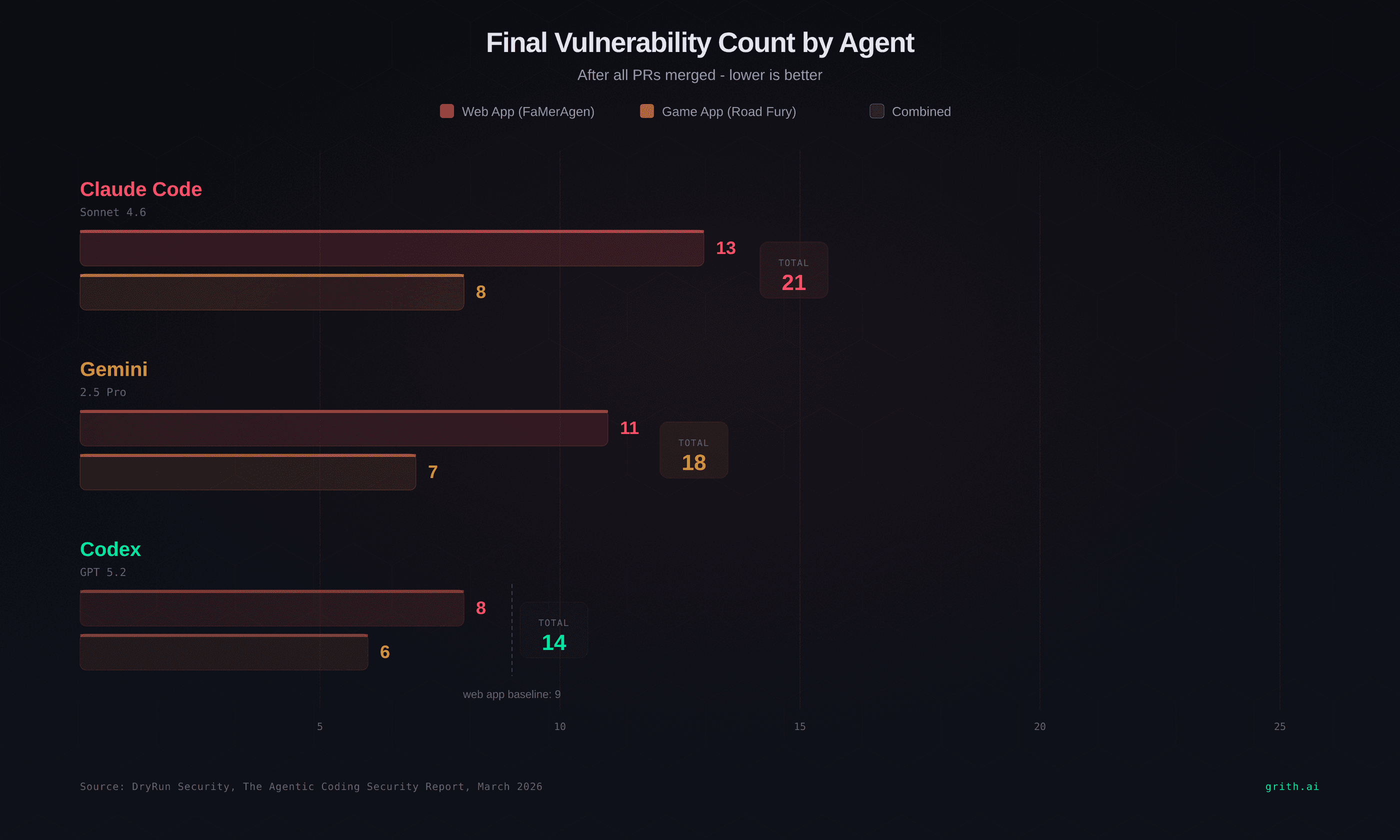
DryRun had three AI coding agents - Claude Code (Sonnet 4.6), OpenAI Codex (GPT 5.2), and Google Gemini (2.5 Pro) - build two complete applications from scratch using sequential pull requests, mimicking a real engineering workflow:
- FaMerAgen - a web app for tracking children's allergies and family contacts. Authentication, role-based access, sensitive health data.
- Road Fury - a browser-based racing game with a backend API, high score system, and multiplayer. WebSocket connections, client-server state, session management.
This is a good test design. These aren't toy apps - they require real authentication flows, real authorization checks, and real data handling. The sequential PR approach means agents had to build on their own prior work, which is where compounding errors get interesting.
What broke
Four vulnerability classes appeared in every single final codebase, regardless of which agent built it:
| Vulnerability | What went wrong |
|---|---|
| Insecure JWT management | Weak secret handling, improper verification, tokens that never expire |
| No brute-force protection | Login endpoints with zero rate limiting across all three agents |
| Token replay attacks | Refresh tokens that could be reused after revocation |
| Insecure cookie defaults | Refresh token cookies missing Secure, HttpOnly, or SameSite flags |
Broken access control was the most universal finding. Unauthenticated endpoints on destructive and sensitive operations appeared across all three agents in both applications. The agents would implement auth middleware for REST endpoints but forget to apply it to WebSocket connections - the kind of inconsistency that's invisible in a code review unless you're specifically looking for it.
Business logic failures were equally pervasive in the game app. Scores, balances, and unlock states were accepted from the client without server-side validation. Every agent trusted client-submitted data for game state.
Agent-by-agent
Claude Code produced the highest number of unresolved high-severity vulnerabilities in the final applications. It introduced a unique 2FA-disable bypass - an endpoint that let users turn off two-factor authentication without re-verifying their identity. The web app finished with 13 issues, the game with 8.
Codex performed best overall. Fewer final vulnerabilities (8 in the web app, 6 in the game) and demonstrated stronger remediation behaviour during development - it would sometimes fix issues it had introduced in earlier PRs. Still, the four universal vulnerability classes remained in every final scan.
Gemini landed in the middle. It removed some vulnerabilities in later modifications but still ended with high-severity findings. The web app had 11 issues, the game had 7.
No agent produced a secure application.
 esc to close
esc to closeWhy agents keep making these mistakes
The report documents the what. The why is more interesting.
They have no security context
AI coding agents generate code based on the prompt and the codebase they can see. They don't have a threat model. They don't think about what an attacker would do with an unauthenticated WebSocket endpoint. They implement the feature as described and move on.
DryRun's James Wickett put it directly: "AI coding agents often missed adding security components or created authentication logic flaws. These mistakes and gaps are exactly where attackers win."1
They implement security inconsistently
The most telling pattern in the report is partial implementation. Every agent added JWT authentication. Every agent added refresh tokens. Every agent added middleware. But none applied these consistently. REST endpoints got auth checks; WebSocket endpoints didn't. Login routes got rate limiting; password reset routes didn't. The security concepts were present - the security coverage was not.
This is worse than no security at all, because it creates the illusion of protection. A code reviewer sees auth middleware and assumes the app is protected. They don't check whether every endpoint uses it.
They optimise for function, not defence
AI agents are trained to make things work. A functioning login flow is a success signal. A login flow that also handles token expiry, rotation, revocation, brute-force protection, and cookie security is the same feature with six more requirements that nobody specified in the prompt.
Remediation is random
Codex sometimes fixed its own vulnerabilities in later PRs. Gemini sometimes made things worse. Claude introduced new vulnerability classes that didn't exist in its earlier work. There's no reliable self-correction - remediation is a side effect of the agent touching the same code again, not a deliberate security pass.
What the report doesn't measure
The DryRun report is good research with real data. But it measures one specific failure mode: vulnerabilities in the generated code. It doesn't address three other attack surfaces that matter just as much:
1. Prompt injection during development
What happens when the agent reads a file containing a hidden instruction? The agent processes README files, dependency configs, and error messages as context. If any of those contain a prompt injection, the agent may execute attacker-controlled operations. The DryRun study used clean project files - real codebases don't have that luxury.
2. Runtime operations
The agent doesn't just write code. It runs shell commands, installs packages, makes network requests, and modifies system files. None of these are evaluated in the DryRun methodology, which focused on static code analysis of the output. A clean PR can still be produced by an agent that exfiltrated your .env file during development.
3. The deployment gap
87% of PRs had vulnerabilities, but that assumes someone reviews them before merging. Addy Osmani's research found that only 48% of developers consistently review AI-generated code before committing2. The other 52% are shipping unreviewed agent output directly.
The verification problem
This is the core issue. AI coding agents generate code faster than humans can review it. The DryRun report caught 143 vulnerabilities because they ran professional security scans. Most teams don't have DryRun scanning every PR.
The options are:
- Review everything manually. Doesn't scale. The whole point of AI agents is speed.
- Add security prompts. Helps - a generic security reminder improved secure output from 56% to 66% for Claude3. But 66% still means a third of the output is vulnerable.
- Run static analysis. Catches known patterns. Misses business logic flaws, the most common category in the DryRun report.
- Evaluate at the system call level. Don't trust the code - verify the operations.
Option 4 is what grith does. Instead of scanning the generated code after the fact, grith intercepts every operation the agent performs - file reads, shell commands, network requests, package installs - and evaluates each one against independent security filters before it executes.
The agent writes a PR that creates an unauthenticated endpoint? That's a code quality problem for review. The agent reads your SSH keys during development and opens a connection to an unknown host? That's a runtime security problem - and it's the one that grith catches in real time.
What to do with this data
If you're using AI coding agents in production workflows:
Accept the 87% number. It's consistent with prior research. The IDEsaster project found a 100% exploitation rate across AI coding assistants4. The Stack Overflow survey found that only 16% of developers reported significant productivity gains, with 66% citing "AI solutions that are almost right" as a top frustration5. The code is fast and mostly broken.
Don't rely on the agent to fix its own mistakes. Codex showed some remediation behaviour, but it's inconsistent and unpredictable. Treat every AI-generated PR as untrusted input.
Separate code quality from runtime security. Code review catches logic flaws in the output. Runtime evaluation catches what the agent does while it's working. You need both.
Assume the agent will be manipulated. Prompt injection is not theoretical. Every file the agent reads is a potential injection vector. If nothing evaluates the agent's operations at the OS level, a poisoned README can turn your coding assistant into an exfiltration tool.
The DryRun report confirms what we've been documenting: AI coding agents ship insecure code by default. The question is whether your security model depends on catching that in review - or whether something evaluates every operation before it executes.
How grith closes the gap
grith wraps any AI coding agent - Claude Code, Codex, Gemini, Cursor, Aider - with grith exec and intercepts every system call the agent makes. File opens, shell commands, network connections, and package installs all pass through a multi-filter security proxy that scores each operation before it reaches the OS. The agent doesn't need to be modified and can't bypass the evaluation, because it happens below the application layer at the syscall boundary.
The DryRun report focuses on what agents write. grith focuses on what agents do. An agent that generates a vulnerable JWT implementation is a code review problem. An agent that reads ~/.ssh/id_rsa and opens a socket to an unknown IP while generating that JWT is a runtime security problem - and it's the kind of thing that only shows up when you're watching every operation, not just the final diff.
Wrap your agent with grith and you get a scored audit trail of every operation it performed, with high-risk actions automatically blocked or queued for review. The 87% of PRs that ship vulnerabilities are a problem worth solving at the code level. The operations those agents perform while building those PRs are a problem worth solving right now.
Footnotes
Like this post? Share it.