Zero Ambient Authority: The Principle That Should Govern Every AI Agent
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
 esc to close
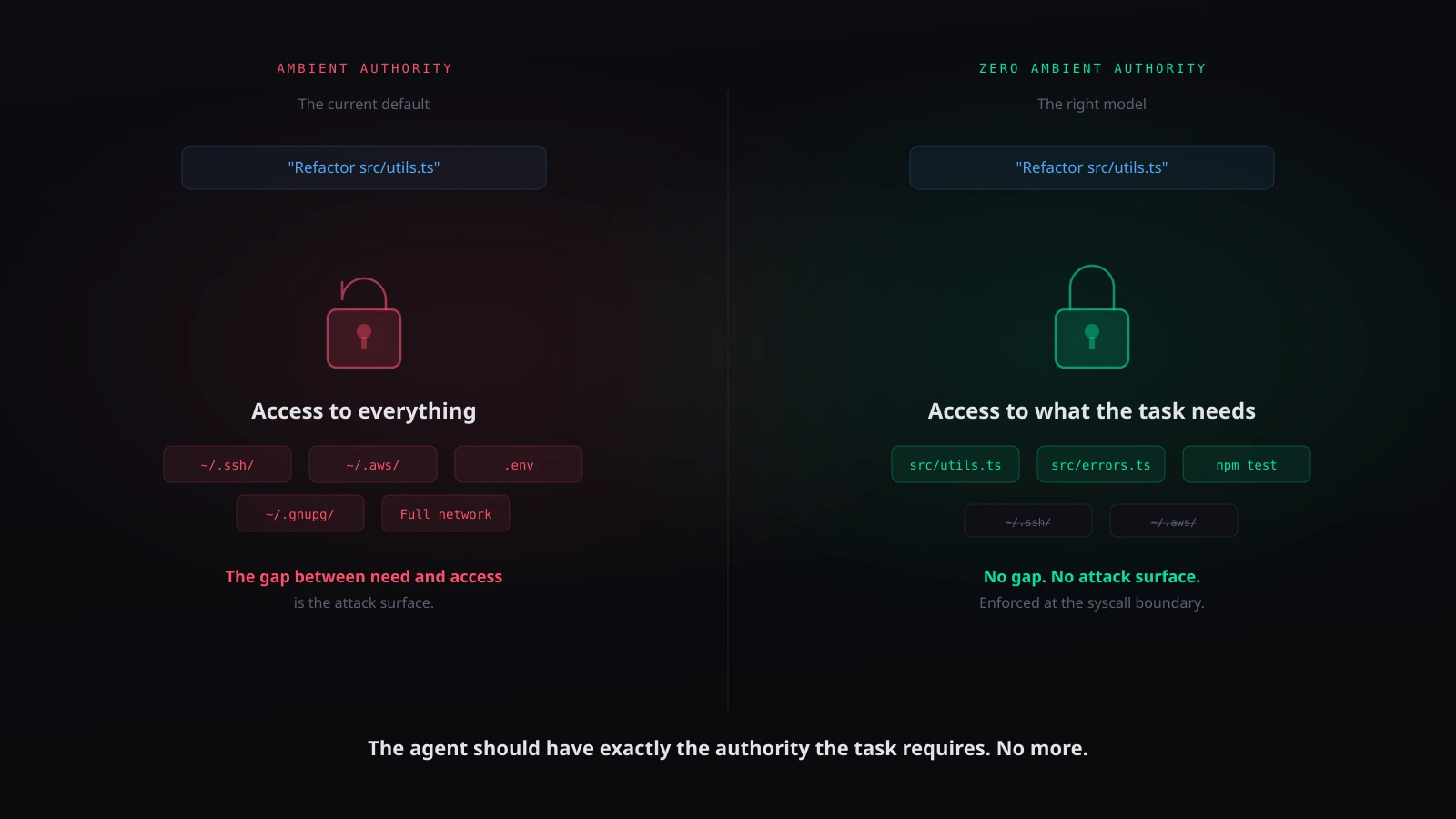
esc to closeWhen you run an AI coding agent, the agent inherits your user session. Every file your user account can read, the agent can read. Every network endpoint your machine can reach, the agent can reach. Every credential stored in your home directory - SSH keys, AWS tokens, GPG keys, browser cookies, database connection strings - the agent can access.
No one grants these permissions. No one reviews them. They are simply there, ambient in the environment, available to any process running under your user ID.
This is ambient authority. It is how Unix processes have worked for fifty years. And it is exactly the wrong security model for AI agents.
What ambient authority means
Ambient authority is a term from capability-based security research1. It describes a system where the ability to perform an action is determined by who is performing it, not by what they were authorized to do for this specific task.
In a Unix system, a process running as user dan can read any file that dan owns. It does not need to declare which files it intends to read. It does not receive a scoped token granting access to specific paths. It simply has access - ambient, implicit, unbounded by task.
This model works tolerably when every process running under your account is a program you chose to run, doing what you told it to do. It breaks down when the process is an autonomous agent that generates its own actions, processes untrusted input, and can be redirected by prompt injection.
The difference is intent. When you run cat ~/.ssh/id_rsa, you intended to read that file. When an AI agent runs cat ~/.ssh/id_rsa, you may have intended nothing of the sort. The agent decided to read it, for its own reasons, using authority it inherited from your session - not authority you granted for this task.
The permission model that every agent uses
Survey the landscape of AI coding agents and the permission model is remarkably uniform:
- Claude Code runs as your shell user. Full filesystem, full network, full process spawning.
- Codex runs in a sandbox by default, but the sandbox is often disabled for full functionality.
- Cursor executes terminal commands as your user, with opt-in approval prompts.
- Aider runs commands directly in your shell session.
- Cline executes with whatever permissions VS Code's terminal has.
Every one of these tools has some mitigation - a permission prompt, an allowlist, a sandbox mode. But the default posture is ambient authority. The agent starts with access to everything, and the mitigations attempt to restrict it after the fact.
This is backwards. The secure default is zero authority. The agent should start with access to nothing and receive explicit grants for the specific resources the task requires.
Why ambient authority fails for agents
The problems with ambient authority are well-understood in capability security literature. For AI agents, three are particularly acute:
1. The authority is broader than the task
You ask the agent to refactor a function in src/utils.ts. The task requires access to a handful of source files. The agent has access to your entire home directory, your SSH keys, your cloud credentials, your browser profile, every secret on your machine.
This is the principle of least privilege2, violated at the architectural level. The gap between what the agent needs and what the agent has is enormous. Every file and credential in that gap is attack surface - accessible through prompt injection, instrumental convergence, or simple model error.
2. The authority is not revocable per-task
Once the agent inherits your session, there is no mechanism to say "for this task, you may access src/ but not .ssh/." The permission model is binary: the agent either has your full session or it does not run.
Some agents implement file-level allowlists, but these are advisory. The allowlist is enforced by the agent's own code - the same code that processes untrusted input and can be redirected by prompt injection. The allowlist is inside the trust boundary, not outside it.
3. The authority is indistinguishable from the user's
When the agent reads a file, the operating system sees your user ID. When the agent makes a network request, the request carries your credentials. When the agent spawns a process, the process runs with your permissions. There is no audit distinction between "the user did this" and "the agent did this."
If the agent exfiltrates data, the logs show your user account making the request. If the agent modifies a production database, the access logs show your credentials. The agent's actions are forensically indistinguishable from yours.
Capability-based security: the alternative
Capability-based security is a model where access to a resource requires an explicit, unforgeable token - a capability - that grants specific permissions to a specific resource3. Instead of asking "who is requesting access?" (ambient authority), the system asks "does the requester hold a valid capability for this resource?" (capability-based authority).
In a capability system:
- Authority is explicit. The agent does not inherit ambient permissions. It receives specific capabilities for specific resources, granted for a specific task.
- Authority is scoped. A capability to read
src/utils.tsdoes not grant access to~/.ssh/id_rsa. Each resource requires its own capability. - Authority is revocable. Capabilities can be revoked at any time - when the task completes, when the session ends, or when the system detects anomalous behaviour.
- Authority is auditable. Every capability grant is a record. You can answer "what did the agent have access to?" definitively, not by inferring from user-level permissions.
This is not a new idea. The capability model was formalized by Dennis and Van Horn in 19664. KeyKOS, EROS, and seL4 implemented it at the OS kernel level. The principle of least authority (POLA) - the application of capability thinking to system design - has been a cornerstone of security architecture for decades5.
What is new is the urgency. When the process running under your account was gcc or vim, ambient authority was an acceptable risk. When the process is an autonomous agent that generates actions from natural language, processes untrusted input, and can be redirected by adversarial instructions, ambient authority is an unacceptable one.
 esc to close
esc to closeWhat zero ambient authority looks like
Zero ambient authority for AI agents means:
1. Default deny. The agent starts with no permissions. It cannot read files, make network requests, or spawn processes until explicitly authorized.
2. Task-scoped grants. When the user asks the agent to refactor src/utils.ts, the agent receives read/write access to the relevant source files and nothing else. Not the home directory. Not the SSH keys. Not the network.
3. Least privilege enforcement at the OS layer. The grants are enforced below the agent, at the syscall boundary. The agent cannot exceed its grants because the enforcement mechanism is outside its trust boundary. A prompt injection can change what the agent wants to access. It cannot change what the enforcement layer allows it to access.
4. Automatic scope reduction. As the task progresses, unused capabilities are revoked. If the agent has not accessed a file in the current session, access to that file is not carried forward.
5. Auditable authority. Every grant, every access, every denial is logged. The audit trail answers not just "what did the agent do?" but "what was the agent authorized to do?"
The counter-arguments
"This will make agents less useful." Yes, in the same way that removing root access makes a developer account less capable. The reduction in capability is precisely targeted at the gap between what the task requires and what the agent can currently access. That gap is where attacks live.
"Developers will not tolerate the friction." The friction argument assumes that capability scoping requires per-action approval prompts. It does not. The right implementation is automatic - the enforcement layer evaluates each action and allows, denies, or queues it without interrupting the developer. The developer reviews only the genuinely ambiguous cases, batched into a digest at their convenience.
"We can just sandbox the agent." Sandboxing is a step in the right direction - it reduces ambient authority by restricting the environment. But a sandbox is a static boundary. It does not distinguish between a legitimate file read and an exfiltration attempt within the sandbox scope. Capability-based enforcement adds per-action evaluation inside whatever boundary the sandbox provides.
"The model providers will solve this with better alignment." Alignment reduces the frequency of harmful actions. It does not bound them. A well-aligned model will attempt harmful actions less often. Zero ambient authority ensures that when it does, the action fails. These are complementary, not competing, strategies.
The policy implication
AI agent security is becoming a governance question. The EU AI Act, NIST AI 600-1, and emerging regulatory frameworks are moving toward requiring risk assessment and mitigation for autonomous AI systems6. Ambient authority - where an agent inherits unbounded permissions by default - is going to be increasingly difficult to defend in a compliance context.
Organizations deploying AI agents internally will need to answer: "What was the agent authorized to access?" Under ambient authority, the answer is "everything the user could access." Under zero ambient authority, the answer is specific, scoped, and auditable.
The principle is simple: an AI agent should have exactly the authority required for its current task, no more, and that authority should be enforced at a layer the agent cannot circumvent.
Implementing zero ambient authority
grith implements this model for local AI agents. Every syscall - file read, network connection, process spawn - passes through a multi-filter scoring pipeline that evaluates whether the action falls within the agent's scoped authority:
- Actions within scope auto-allow. No prompt. No interruption.
- Actions clearly outside scope auto-deny. The agent sees a permission failure.
- Actions in the ambiguous middle queue into a quarantine digest for human review at the developer's convenience.
The agent does not know the enforcement layer is there. It has no capability to probe it, reason about it, or circumvent it. The enforcement is below the trust boundary - invisible, consistent, non-negotiable.
This is not a sandbox. It is not an allowlist. It is per-action enforcement informed by context - what file, what destination, what command, what the agent has done so far in this session - evaluated in under 15ms per syscall.
Zero ambient authority is not a feature. It is a principle. And it is the principle that should govern every AI agent that runs on your machine.
One command to apply it: grith exec -- <your-agent>.
Footnotes
-
Miller, M., Yee, K., Shapiro, J.: Capability Myths Demolished (Technical Report, Johns Hopkins University, 2003) ↩
-
Saltzer, J., Schroeder, M.: The Protection of Information in Computer Systems (Proceedings of the IEEE, 1975) ↩
-
Levy, H.: Capability-Based Computer Systems (Digital Press, 1984) ↩
-
Dennis, J., Van Horn, E.: Programming Semantics for Multiprogrammed Computations (Communications of the ACM, 1966) ↩
-
Miller, M.: Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control (PhD Dissertation, Johns Hopkins University, 2006) ↩
-
NIST: Artificial Intelligence Risk Management Framework: Generative AI Profile (NIST AI 600-1, 2024) ↩
Like this post? Share it.