NemoClaw vs grith: Sandbox for One Agent vs Security for All
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
 esc to close
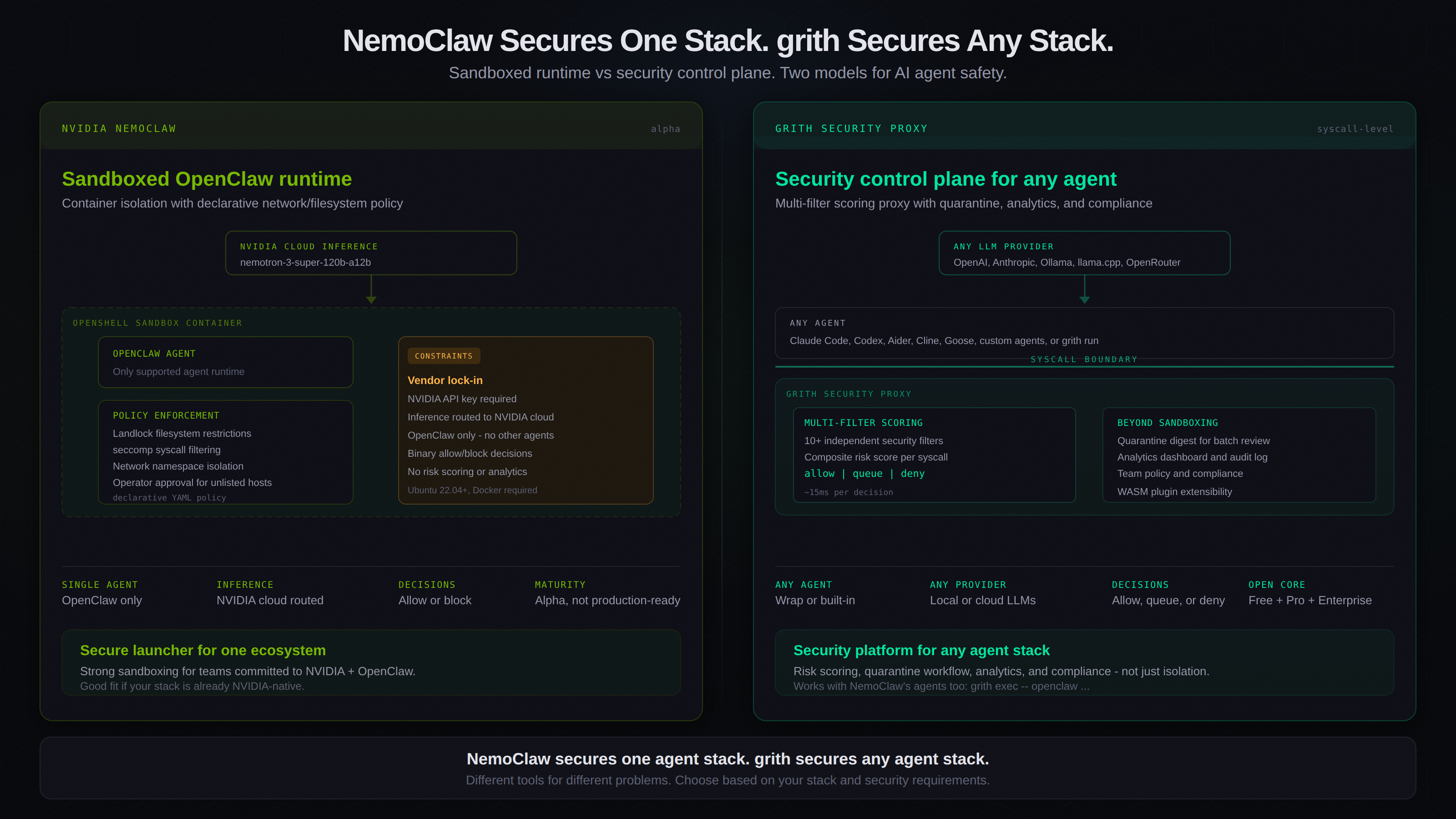
esc to closeNVIDIA recently launched NemoClaw - an orchestration plugin for running OpenClaw agents inside a sandboxed environment. It uses OpenShell containers with Landlock, seccomp, and network namespace isolation to enforce security policy around agent execution.
It is a serious project with real security engineering behind it. It also solves a narrower problem than grith does.
This is not a takedown. Both tools exist because the same underlying problem is urgent: AI agents execute code with too much ambient authority, and the industry needs enforcement mechanisms that do not depend on the agent policing itself. NemoClaw and grith agree on that premise. They differ on scope, architecture, and who they are built for.
What NemoClaw does
NemoClaw is best described as a secure launcher for OpenClaw. It wraps the OpenClaw agent in an OpenShell sandbox container and enforces four categories of policy:
| Layer | Mechanism | Mutability |
|---|---|---|
| Network | Operator-approved allowlist, TLS enforcement | Hot-reloadable |
| Filesystem | Landlock - writes locked to /sandbox and /tmp | Locked at creation |
| Process | seccomp syscall filtering | Locked at creation |
| Inference | Requests routed through NVIDIA cloud gateway | Hot-reloadable |
When the agent attempts to reach an unlisted host, OpenShell blocks the connection and prompts the operator in the TUI for approval. Policy is declarative YAML. Decisions are binary: allow or block.
The sandbox implementation is solid. Landlock and seccomp are battle-tested Linux kernel security features, and NemoClaw applies them correctly.
Where NemoClaw stops
NemoClaw is designed for one workflow: run OpenClaw safely inside NVIDIA infrastructure. That means:
- Single agent support. NemoClaw only works with OpenClaw. You cannot use it with Claude Code, Codex, Aider, Cline, or any other coding agent.
- Vendor-locked inference. All model requests are transparently rerouted to NVIDIA's cloud, using NVIDIA API keys and Nemotron models. There is no option for local inference, OpenAI, Anthropic, or OpenRouter.
- Binary decisions. Every action is either allowed or blocked. There is no risk scoring, no graduated response, no quarantine for human review.
- No analytics or audit. NemoClaw does not produce structured audit logs, compliance reports, or usage analytics. Operator visibility is limited to the TUI.
- Alpha maturity. The README explicitly states the project is not production-ready and that APIs may change without notice.
These are not criticisms. They are scope decisions. NemoClaw chose to solve one problem well rather than build a platform. That is a valid engineering choice.
What grith does differently
grith is not a sandbox launcher. It is a security proxy that sits between any AI agent and the operating system, intercepting syscalls and evaluating every tool call against a multi-filter scoring pipeline.
Any agent, any provider
grith works in two modes:
grith run- a built-in LLM agent with proxy-mediated tool executiongrith exec- wraps external tools like Claude Code, Codex, Aider, Cline, or Goose
Both modes share the same security pipeline. The agent does not matter. The enforcement is the same.
For inference, grith routes to any provider - Ollama, llama.cpp, OpenAI, Anthropic, OpenRouter - or runs fully local. There is no vendor lock-in at the model layer.
Scoring, not just blocking
The most significant architectural difference is how decisions are made.
NemoClaw uses static policy: a syscall or network request either matches an allowlist or it does not. grith runs every intercepted action through 10+ independent security filters and produces a composite risk score:
| Score range | Action | What happens |
|---|---|---|
| 0.0 - 3.0 | Allow | Action executes immediately |
| 3.0 - 7.0 | Queue | Action held for human review in digest |
| 7.0 - 10.0 | Deny | Action blocked, logged, never executes |
This three-tier model means grith does not need to constantly interrupt the developer. Low-risk actions flow through. High-risk actions are blocked. The middle ground - the ambiguous calls that might be legitimate or might be an attack - is collected into a quarantine digest for batch review.
That distinction matters in practice. Binary allow/block systems either over-block (causing approval fatigue) or under-block (missing novel attacks). Scored decisions with quarantine provide a workflow that scales.
Audit, analytics, and compliance
Every tool call that passes through grith produces a structured JSON audit record: what was attempted, which filters triggered, what scores were produced, and what decision was made. These records feed into:
- A web dashboard with session summaries and analytics
- Team-wide policy management and shared configurations
- Compliance reporting for enterprise governance requirements
NemoClaw does not have an equivalent. Its observability is limited to the operator TUI and sandbox logs.
Side-by-side
| Dimension | NemoClaw | grith |
|---|---|---|
| Agent support | OpenClaw only | Any agent (Claude Code, Codex, Aider, Cline, Goose, custom) |
| LLM providers | NVIDIA cloud only | Any - local or cloud |
| Decision model | Binary allow/block | Scored allow/queue/deny |
| Security mechanism | Container sandbox (Landlock, seccomp, netns) | Syscall interception + multi-filter scoring proxy |
| Review workflow | Operator TUI prompt per blocked action | Quarantine digest for batch review |
| Audit | Sandbox logs | Structured JSON per syscall, analytics dashboard |
| Team features | None | Policy management, shared configs, compliance |
| Extensibility | Declarative YAML policy | WASM plugin system |
| Commercial model | Open-source (Apache 2.0) | Open-core (free single-user, Pro $25/user/mo, Enterprise) |
| Maturity | Alpha | Production |
When to use which
Use NemoClaw if:
- Your team is already committed to OpenClaw and NVIDIA infrastructure
- You want strong container-level isolation for a single agent
- You are comfortable with binary allow/block decisions
- You do not need analytics, compliance, or team governance features
Use grith if:
- You run multiple AI coding agents or want the flexibility to switch
- You need vendor-neutral inference routing
- You want graduated risk decisions instead of binary blocking
- You need audit trails, analytics, or compliance reporting
- You are building for a team, not just a single developer
Use both if:
- You want NemoClaw's container isolation as one layer, with grith providing scoring and analytics on top:
grith exec -- openclaw ...
The bigger picture
The fact that NVIDIA is building agent security tooling validates the problem space. AI agents operating with unchecked ambient authority is a real and growing risk. The industry needs multiple approaches, and both NemoClaw and grith contribute to solving it.
The architectural question is whether sandboxing alone is sufficient, or whether you also need a decision engine that scores risk, batches ambiguous calls for review, and produces audit trails. For a single agent in a controlled environment, sandboxing may be enough. For teams running multiple agents across different providers and projects, you need a security control plane.
NemoClaw secures one agent stack. grith secures any agent stack.
Like this post? Share it.