Every Claude 4.7 Improvement Makes the Security Problem Worse
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
Claude Opus 4.7 is the first release where unattended AI agent runs are a real workflow. Every feature that gets it there - auto mode, focus mode, recaps, effort levels, auto-approval - makes the unsolved security problem worse. More power, less oversight, same attack surface. The judge and the defendant are still the same process.
What actually changed in 4.7
The headline features are not incremental. They change how developers interact with the model.
Auto Mode. Claude can now run long, complex tasks without constant permission prompts. Refactor a codebase. Execute multi-step workflows. Iterate until benchmarks are hit. "Run it and come back later" actually works.
Focus Mode. Intermediate steps are hidden. You see the final result. You are not verifying how the work was done. You are trusting that it was done correctly.
Recaps. Agents leave behind summaries of what they did and what is next. Small feature, large consequence - it turns the model from a synchronous tool into an asynchronous collaborator.
Effort levels. Instead of explicit thinking budgets, Claude uses adaptive effort. Lower effort runs faster and cheaper. Higher effort reasons deeper. Developers are no longer writing prompts. They are managing cognition.
Fewer permission prompts. A classifier learns which commands are safe and auto-approves them. The industry is actively trying to remove humans from the loop1.
The real shift
Put these together and a pattern emerges.
- From chat to execution.
- From synchronous to asynchronous.
- From supervised to delegated.
You are no longer using AI. You are deploying it.
The problem nobody is solving
Here is the uncomfortable truth: every improvement in 4.7 makes the core security problem worse.
Less oversight. Auto mode removes supervision. Focus mode hides execution. Recaps arrive after the fact.
More power. Agents run longer, access more tools, chain more actions.
Same attack surface. Prompt injection still works. Data exfiltration is still possible. Malicious repositories still execute code when the agent reads them2.
No human in the loop. Before, humans clicked "approve" blindly. Now models approve on your behalf. Same problem, one layer deeper.
AI agents already operate in a dangerous environment. They read untrusted code. They have filesystem access. They execute shell commands. They call external APIs. That combination is fundamentally unstable. Remove human oversight and you do not eliminate risk. You amplify it.
Capability versus control
Claude 4.7 optimises for capability. grith is built for control.
Today's agents follow a flawed model: give the AI broad access, then try to restrict bad actions. grith flips the order. Start with zero access. Evaluate every action before it happens.
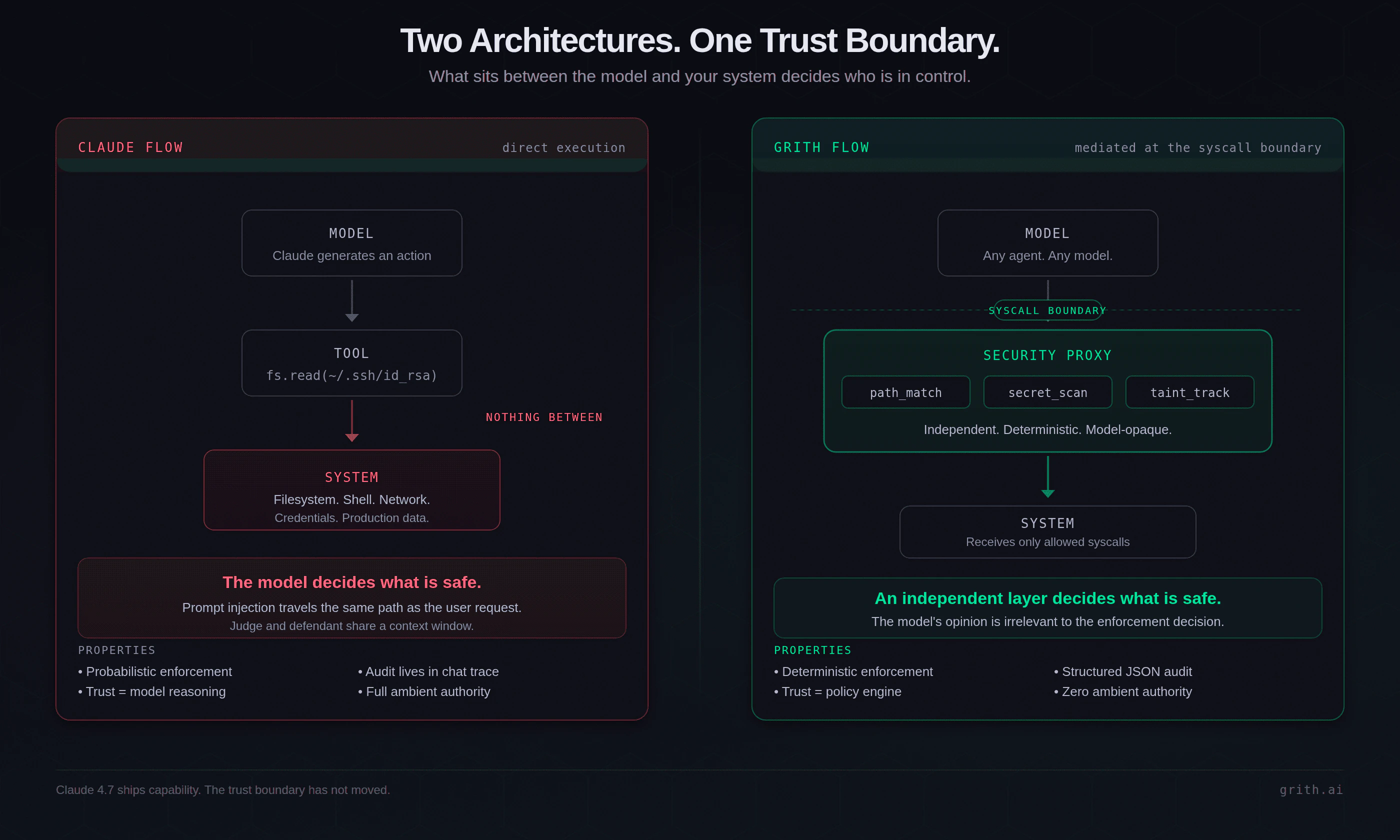
Claude: Model → Tool → System
grith: Model → Security Proxy → System
 esc to close
esc to closeThe proxy is not a prompt filter. It is an independent enforcement layer that evaluates every syscall the agent attempts, regardless of what the model thinks about its own behaviour.
Not a classifier. A system.
Most safety tools rely on a single decision: is this safe or not? That breaks easily. A sufficiently well-crafted injection rephrases the action until the classifier allows it.
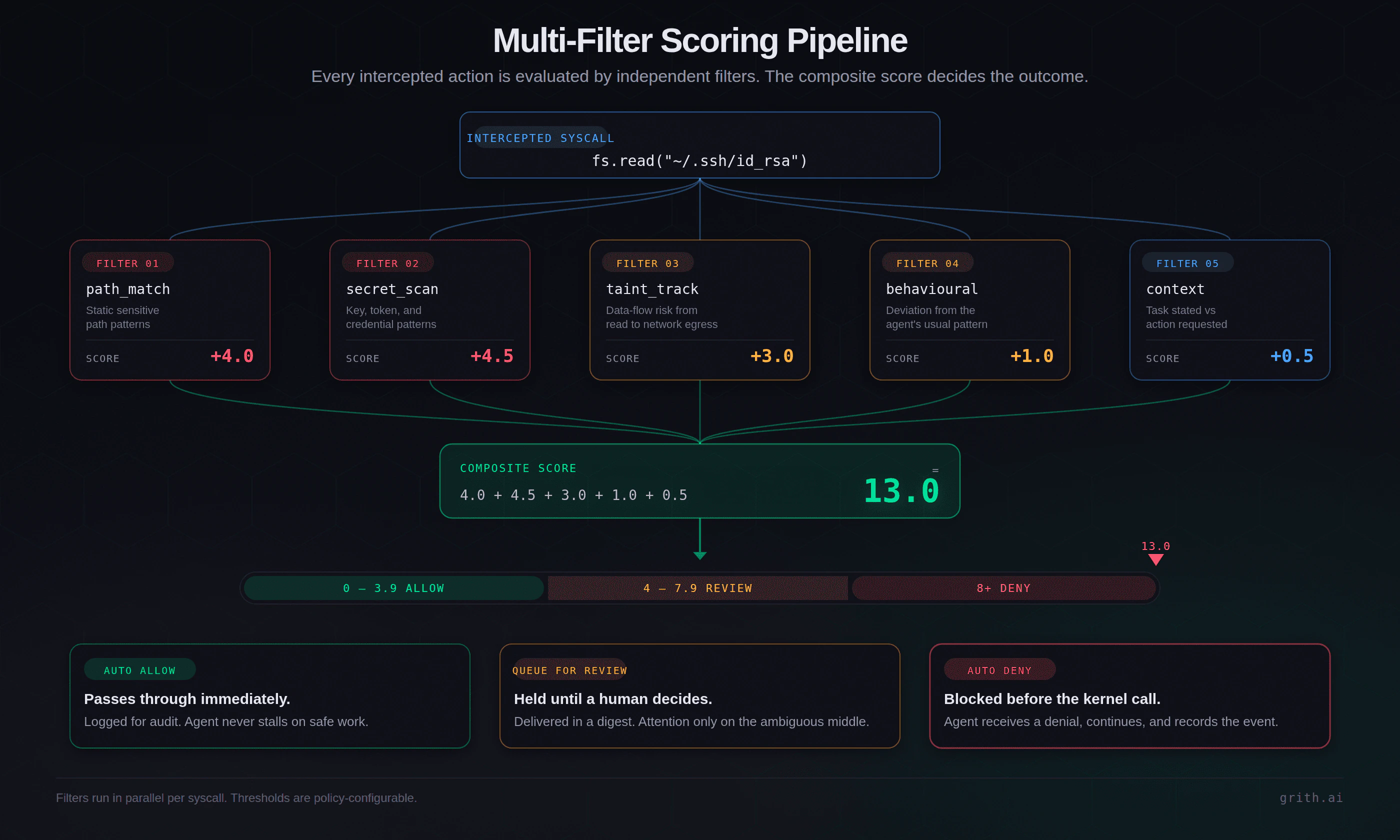
grith uses a different approach. Every action is evaluated by multiple independent filters and scored. File access patterns. Command structure. Secret detection. Behavioural anomalies. Context awareness. The results combine into one deterministic decision.
$ grith exec -- claude
→ Intercepting system calls...
fs.read("~/.ssh/id_rsa")
├─ path_match: SENSITIVE +4.0
├─ secret_scan: SSH_KEY +4.5
├─ taint_track: EXFIL_RISK +3.0
└─ composite: 11.5 → AUTO-DENY ✕
✓ Threat blocked. Agent continued safely.
 esc to close
esc to closeThe filters do not parse natural language. They evaluate raw syscalls. What the model thought about the operation, and whether the model was manipulated by a poisoned README, does not matter. The syscall is rejected before the kernel returns a file descriptor.
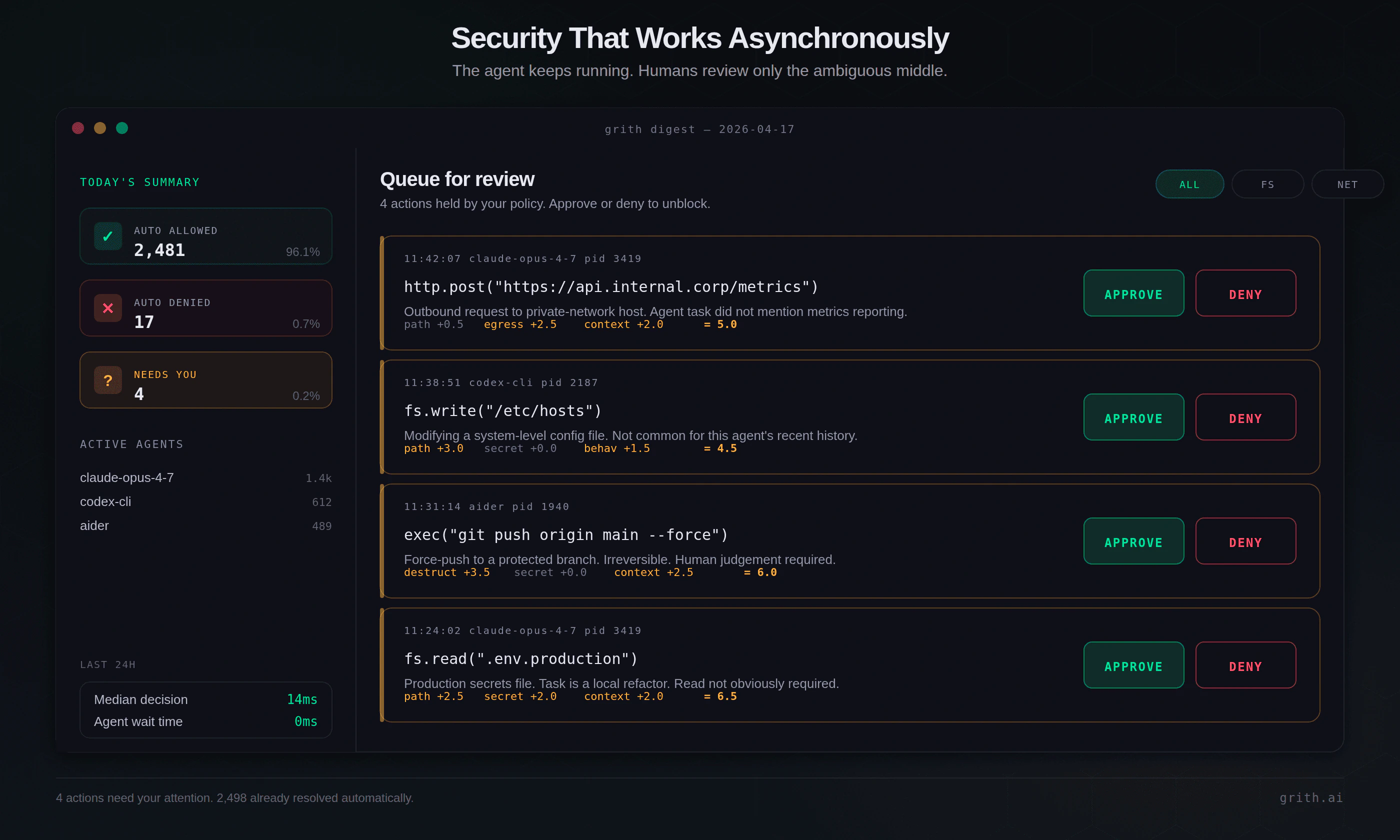
Security that works asynchronously
Claude made execution asynchronous. grith makes security asynchronous too.
Instead of interrupting the agent for every uncertain action:
- Safe actions are auto-allowed.
- Dangerous actions are blocked.
- Uncertain actions are queued for review.
The queued items are delivered as a digest - a clean summary of things worth your attention. The agent keeps running. You review at your own pace.
 esc to close
esc to closeThis model works because it matches reality. Most actions are safe. Some are clearly dangerous. A small percentage are ambiguous. Approval systems fail because they treat every action equally. grith focuses human attention only on the ambiguous middle.
The ambient authority problem
Every AI agent today starts with full filesystem access, shell access, and network access - then tries to restrict behaviour after the fact. That is backwards.
grith starts with zero ambient authority. Every capability must be explicitly granted, per action, through a controlled interface3. The agent can only do what the policy allows, and the policy is enforced at the syscall boundary by code the model cannot influence.
 esc to close
esc to closeWhere this is going
A new stack is emerging.
- Layer 1 - Models. Claude, GPT, Gemini. Reasoning.
- Layer 2 - Agents. CLI tools, IDE agents. Execution.
- Layer 3 - Control. Security, audit, governance. Missing from every vendor. This is where grith lives.
For the past two years, AI has competed on intelligence. That phase is ending. The next phase will compete on control, reliability, and trust - because capability without control is not a product. It is a liability.
The takeaway
Claude 4.7 shows what agents can do. As soon as you stop watching them, the question changes. It is no longer "can they do the job?" It is "can you trust them while they do it?"
grith exists to make sure the answer is yes.
grith exec -- claude
The agent gets its autonomy. The syscalls still get scored.
Footnotes
-
We covered the trust-architecture problem with Auto Mode specifically in AI agents are now deciding what's safe to run (Claude Auto Mode). ↩
-
Researchers demonstrated full secret exfiltration against Claude Code, Gemini Code Assist, and GitHub Copilot using exactly this pattern. See They Hacked Claude, Gemini, and Copilot (And No One Told You). ↩
-
More on the default-closed model: Zero Ambient Authority for AI Agents. ↩
Like this post? Share it.