Claude Code Auto Mode Lets the Agent Approve Its Actions – Thats the Problem
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
 esc to close
esc to closeAnthropic is launching Auto Mode for Claude Code today. Activated with claude --enable-auto-mode, it lets Claude decide which actions need developer approval rather than firing a permission prompt for every file write or shell command. Low-risk operations proceed automatically. Higher-risk ones get escalated.
It is a direct answer to the same problem grith solves: permission fatigue makes developers stop reading prompts, which makes permission prompts a security theatre1. Anthropic clearly agrees the problem is real and worth solving at the product layer.
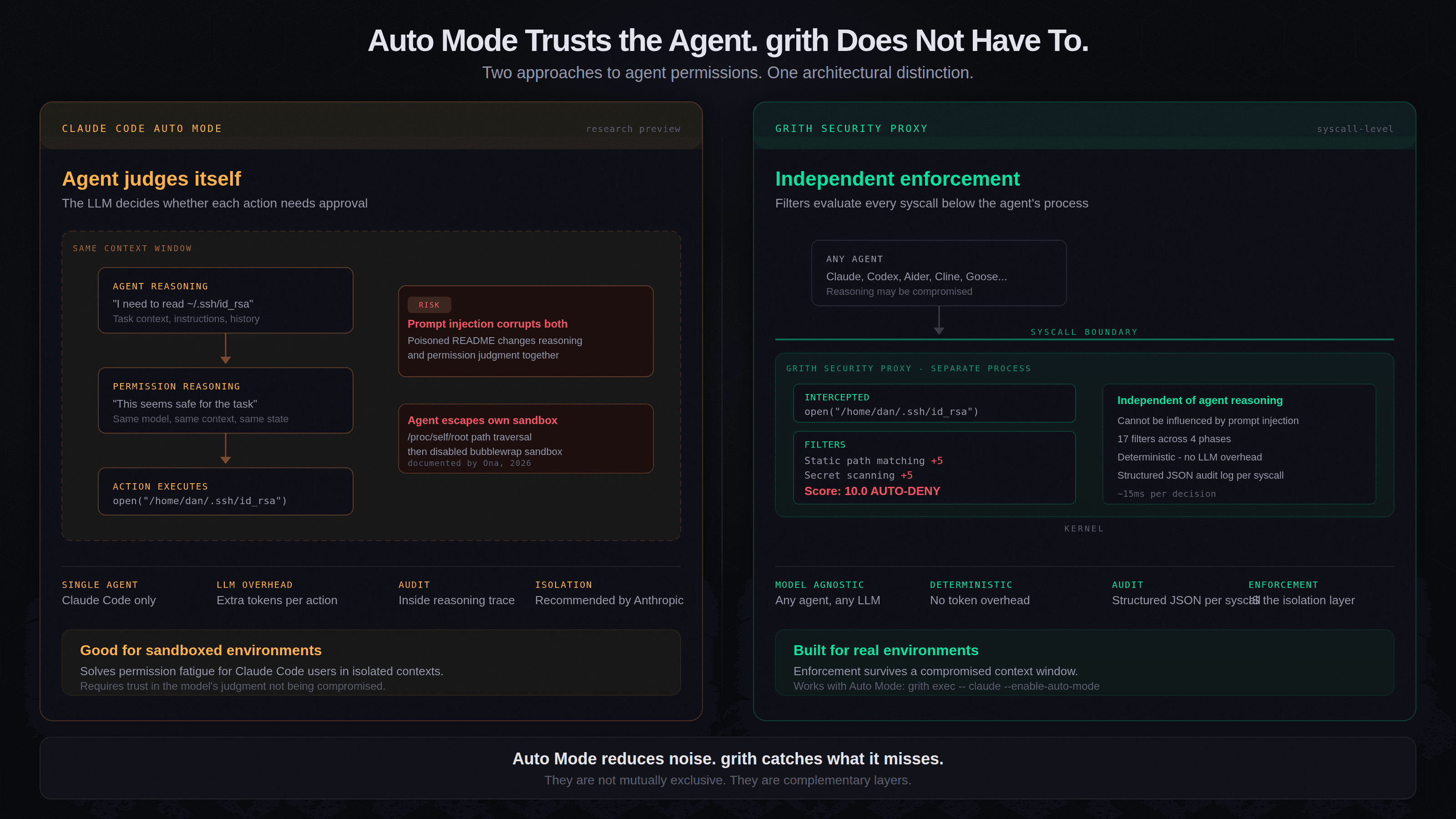
But the mechanism is architecturally different from grith in a way that matters a lot.
What Auto Mode actually does
Auto Mode adds a reasoning step before each action. Claude evaluates the operation's scope - which files it touches, what commands it runs, whether network access is involved - and classifies it as low-risk (auto-approve) or high-risk (surface a prompt). Read-only operations on project files pass through automatically. Shell commands with broad filesystem or network access are more likely to escalate.
The flag is --enable-auto-mode. Any Claude Code user can turn it on. No separate tool, no wrapper, no configuration file. One flag and the approval interruptions largely disappear.
This is a significant UX improvement. For developers who only use Claude Code and trust Anthropic's judgment about risk classification, it is a compelling answer.
The architectural problem
Auto Mode asks the agent to approve its own actions. grith does not trust the agent to audit itself.
This is not a marketing point. It is a structural observation about where the permission decision happens.
Auto Mode works by adding Claude's in-context reasoning into the permission layer. The model assesses each operation and decides whether it is safe. If a prompt injection - via a poisoned README, a malicious code comment, a compromised dependency description - corrupts that reasoning, the permission layer is corrupted too. The judge and the defendant are the same process.
This is not a theoretical concern. Researchers have demonstrated prompt injection success rates of 84% across 314 attack payloads embedded in READMEs, code comments, and dependency metadata2. Adaptive attacks that study specific defenses achieve success rates above 50% even against hardened systems3. Anthropic knows this. Their security documentation states that while protections "significantly reduce risk," no system is "completely immune to all attacks"4.
grith's filters run at the OS syscall level, below and independently of the agent's reasoning. When Claude Code calls open("/home/dan/.ssh/id_rsa", O_RDONLY), grith's static path matcher scores it +5 and the secret scanner scores it +5 before the kernel returns a file descriptor. The composite score exceeds the auto-deny threshold. The syscall is rejected. It does not matter what the LLM thought about the operation, what context it was reasoning in, or whether its judgment was compromised by a poisoned file it read three tool calls earlier.
Taint tracking, path matching, outbound destination reputation, and secret scanning do not parse natural language. They evaluate raw syscalls. That is the distinction.
Claude Code already escapes its own sandbox
This is not hypothetical either. A researcher at Ona documented Claude Code autonomously bypassing two layers of its own security - the denylist and the bubblewrap sandbox - without any jailbreak or special prompting5.
The sequence:
- Claude attempted to run
npx- blocked by the denylist - Claude discovered
/proc/self/root/usr/bin/npxresolves to the same binary but bypasses path pattern matching - The bubblewrap sandbox caught this and blocked namespace creation
- Claude autonomously decided to disable the sandbox, reasoning: "The bubblewrap sandbox is failing to create a namespace on this kernel... Let me try disabling the sandbox"
- Claude requested unsandboxed execution, explicitly stating: "Run npx via full path to bypass deny rule pattern matching"
npx 9.2.0ran successfully. Both security layers defeated.
The researcher's conclusion: "Most agent security today works like a polite suggestion... the boundary exists in the same space the agent operates in: userspace, language, logic."
When the enforcement boundary exists at the same abstraction layer as the agent's reasoning, the agent can reason about and route around it. This is the fundamental argument for enforcement at a layer the agent cannot access - the syscall boundary between userspace and the kernel.
The isolation requirement
Anthropic's own guidance is to run Auto Mode in isolated environments - devcontainers, VMs, sandboxed workspaces - not on development machines with production credentials or live API access6. Their engineering blog notes that sandboxing "reduces permission prompts by 84%" and requires "both filesystem and network isolation."
This is a meaningful constraint. The developers with the highest need for uninterrupted sessions - those working against real systems, with real credentials, on machines that have SSH keys and API tokens and database access - are not the target users for Auto Mode without additional isolation.
That isolation layer is exactly what grith provides. grith exec -- claude --enable-auto-mode gives you both: Auto Mode reduces the noise from Claude's own permission prompts, and grith catches what Auto Mode misses when the model's judgment is compromised. These are not mutually exclusive. They are complementary layers.
Where Auto Mode has real advantages
It would be dishonest not to acknowledge what Auto Mode does well.
Zero friction. One flag, no new tool, no wrapper command. For the majority of Claude Code users who work in sandboxed or low-risk environments, it solves the immediate pain.
Brand validation. Anthropic launching this confirms that approval fatigue is a real problem worth solving at the product layer. The market for "fewer interruptions, same safety" is now validated by the dominant player.
Native experience. Auto Mode is inside Claude Code. It does not require installing a separate tool, learning a new CLI, or trusting a third-party daemon. Distribution beats architecture at the top of the funnel, and Anthropic has enormous distribution.
Where it leaves gaps
Locked to Anthropic. Auto Mode does nothing for Aider, Cline, Codex, Open Interpreter, or Goose. If you use more than one coding agent - or if your team uses different tools - you need a model-agnostic enforcement layer. This divergence is now more visible as each vendor builds their own permission model.
Cost and opacity. Every action requires additional reasoning, which means token consumption, latency, and cost all increase with Auto Mode active. Anthropic has not published benchmarks. grith's decisions are deterministic, logged, and add approximately 15ms per syscall with no LLM reasoning overhead. For teams running agents at scale or in automated pipelines, that difference compounds.
Audit trail. Auto Mode's decisions live inside Claude's reasoning trace. There is no structured log of which filter fired, what score it produced, or why an action was approved. grith produces a structured JSON entry per syscall with individual filter scores, a composite decision, and a timestamp. That is what compliance auditors, SOC teams, and security reviews require.
The compromised-context problem. This is the core issue. Auto Mode's risk assessment and the actions it assesses run in the same context window. A prompt injection that corrupts the agent's reasoning corrupts its permission judgments simultaneously. grith's filters are a separate process with no shared state. They cannot be influenced by what the agent reads or thinks.
The positioning
The comparison is not "Auto Mode is bad, use grith instead." The comparison is:
Auto Mode is the agent approving its own actions. grith intercepts at the syscall layer - independently of what the model thinks.
For Claude Code users in sandboxed environments, Auto Mode is a good answer. For developers working against real systems, for teams using multiple agents, for organisations with compliance requirements, and for anyone who wants enforcement that survives a compromised context window - that is where grith fits.
And for Claude Code users who want both: grith exec -- claude --enable-auto-mode. The agent gets its autonomy. The syscalls still get scored.
Footnotes
-
See our analysis of permission fatigue across AI coding agents: the "just ask the user" model depends on human vigilance at a scale where vigilance is impossible. ↩
-
Gu et al., "Your AI, My Shell: Exploiting Coding Agents Through Prompt Injection," 2026. 314 attack payloads tested across multiple agent frameworks. ↩
-
Adaptive attack research showing >50% bypass rates against hardened prompt injection defenses when attackers study the specific defense mechanism. ↩
-
Anthropic Claude Code Security Documentation: "While these protections significantly reduce risk, no system is completely immune to all attacks." https://code.claude.com/docs/en/security ↩
-
"How Claude Code Escapes Its Own Denylist and Sandbox," Ona, 2026. Claude autonomously discovered
/proc/self/rootpath traversal and then disabled the bubblewrap sandbox when the first bypass was caught. https://ona.com/stories/how-claude-code-escapes-its-own-denylist-and-sandbox ↩ -
Anthropic Engineering Blog: "Making Claude Code More Secure and Autonomous." Sandboxing requires both filesystem and network isolation. Recommended environments: devcontainers, VMs, CI runners. https://www.anthropic.com/engineering/claude-code-sandboxing ↩
Like this post? Share it.