Prompt Injection Is Unfixable (So We Stopped Trying)
A security proxy for AI coding agents, enforced at the OS level. Register your interest to be notified when we go live.
 esc to close
esc to closeEvery major AI lab knows this. They just don't say it.
Prompt injection - the ability to override an AI system's instructions by embedding malicious text in its input - is not a bug that will be patched in the next model release. It is a structural property of how large language models work. It cannot be fixed without breaking the capability that makes LLMs useful in the first place: following instructions in natural language.
The industry has spent three years trying to solve it at the model layer. The consensus among researchers is now clear: it cannot be solved there1.
So grith stopped trying. We built an architecture that assumes the model will be compromised and contains the damage when it is.
The consensus is in
In February 2025, the Center for Internet Security published a report on AI agent threats that classified prompt injection as an "inherent threat" - not a vulnerability to be patched, but a fundamental property of the technology2.
They were not being dramatic. They were being precise.
The OWASP Top 10 for LLM Applications has ranked prompt injection as the #1 vulnerability since its first edition in 2023. It remains #1 in the 2025 revision. Not because nobody is working on it. Because nobody has fixed it.
Google DeepMind researchers demonstrated in 2024 that instruction-hierarchy defenses - where the model is trained to prioritize system prompts over user input - can be bypassed with adaptive attacks that achieve near-100% success rates against every tested defense3. The defenses raise the bar from trivial to moderate. They do not eliminate the attack class.
Simon Willison, who coined the term "prompt injection" in 2022, wrote in 2025: "I don't think prompt injection will ever be fully solved... it's an inherent limitation of the way these models work." Mark Russinovich, CTO of Microsoft Azure, said it directly at Ignite 2024: "I don't think we're going to solve it completely. I think it's always going to be a cat-and-mouse game."
This is not a fringe position. It is the emerging mainstream view among security researchers, and the labs know it.
Why it cannot be fixed
The reason prompt injection resists patching is architectural, not incidental.
LLMs process all input as a single stream of tokens. There is no hardware-enforced boundary between "trusted instructions from the developer" and "untrusted content from the environment." The model sees both as text. It decides what to follow based on statistical patterns learned during training.
You can fine-tune the model to resist common injection patterns. Researchers have tried this extensively. The result is always the same: the defense works against known attacks and fails against novel ones3. This is the same dynamic as signature-based malware detection, which the security industry abandoned two decades ago in favor of behavioral analysis.
The fundamental problem is that you are asking the model to simultaneously:
- Follow natural language instructions (its core capability)
- Refuse to follow certain natural language instructions embedded in its input (the defense)
These goals are in direct tension. Any model capable enough to be useful as an agent is capable enough to be manipulated by adversarial input. Making the model "smarter" does not help - it makes it better at following instructions, including injected ones.
The defense-in-depth illusion
The standard industry response is "defense in depth" - layer multiple prompt-level defenses and hope the combination catches what individual layers miss. Input filtering. Output filtering. Instruction hierarchy. Canary tokens. Prompt guards.
Each of these has been individually defeated:
- Input filtering fails against encoded, obfuscated, or multi-step injections
- Output filtering fails when the model exfiltrates data through side channels (tool calls, URLs, file writes)
- Instruction hierarchy fails against adaptive attacks, as DeepMind demonstrated3
- Canary tokens fail when the attacker instructs the model to strip them
- Prompt guard models introduce their own attack surface and add latency without guarantees
Layering five unreliable defenses does not give you reliability. It gives you complexity, false confidence, and an attack surface that grows with every layer you add.
This is not defense in depth. It is defense in hope.
The paradigm shift
The security industry solved an analogous problem decades ago with network security. The old model: build a perfect perimeter, keep attackers out. The new model: assume breach, limit blast radius.
Zero Trust Architecture did not make firewalls unnecessary. It made them insufficient. The same shift is overdue for AI agent security.
The question is not "how do we prevent the model from being manipulated?" The question is: "when the model is manipulated, what can it actually do?"
This is the difference between:
- Prevent bad prompts - try to stop the injection from reaching the model
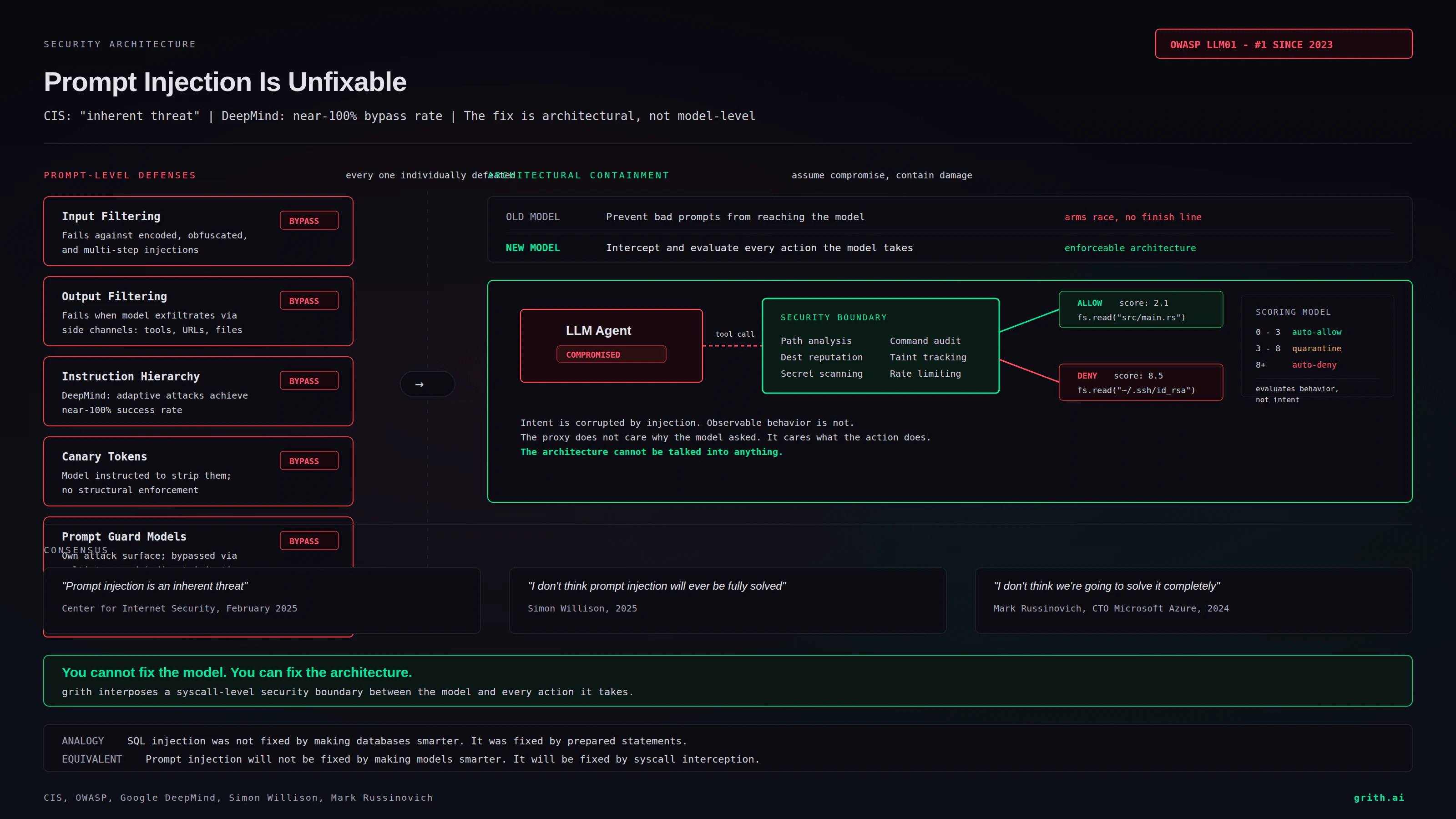
- Assume compromise, contain damage - let the model think whatever it wants, but intercept and evaluate every action it takes
The first approach is an arms race with no finish line. The second is enforceable architecture.
What containment looks like
If you accept that prompt injection is unfixable at the model layer, the security boundary must move from the prompt to the action.
This means every tool call an AI agent makes - every file read, file write, shell command, network request, API call - must be independently evaluated against a security policy before it executes. The evaluation cannot depend on the model's intent, because intent is exactly what prompt injection corrupts.
It must depend on observable facts:
- What file path is being accessed? Is it in scope for this task?
- What command is being executed? Does it match allowed patterns?
- What network destination is being contacted? Is it on the allowlist?
- What data is flowing from where to where? Does the flow match expected patterns?
This is what grith does. Every tool call passes through a multi-filter scoring proxy that evaluates observable behavior - paths, commands, destinations, data flows - against security policy. The proxy does not care whether the model's reasoning was corrupted by an injection. It cares whether the resulting action is safe.
A model compromised by prompt injection that tries to read ~/.ssh/id_rsa gets the same auto-deny as a model that tries it for any other reason. The file path matches a sensitive pattern. The score exceeds the threshold. The action is blocked. The injection succeeded at corrupting the model's intent but failed at causing damage.
The labs know this
OpenAI, Anthropic, and Google have all acknowledged the problem in their own ways. OpenAI's GPT-4 system card lists prompt injection as an unsolved problem. Anthropic's model spec notes that behavioral training does not eliminate adversarial manipulation. Google's A2A protocol shipped with zero prompt injection defenses at the protocol level, deferring the problem entirely to implementers4.
The labs are not being negligent. They are being honest (quietly). Prompt injection is a property of the technology, not a flaw in their implementation. No amount of RLHF, red-teaming, or instruction hierarchy training will eliminate it.
What the labs are not doing is telling developers to stop relying on prompt-level defenses as their primary security mechanism. That message would undermine the "AI agents are ready for production" narrative.
So the message has to come from the security side.
Stop trying to fix the model
Prompt injection is unfixable. Not "hard to fix." Not "needs more research." Unfixable - in the same way that SQL injection is unfixable by making databases smarter. You fix SQL injection by using prepared statements: an architectural change that makes the vulnerability class structurally impossible.
The equivalent for AI agents is not smarter models. It is architecture that interposes a security boundary between the model and the actions it can take. A boundary that evaluates behavior, not intent. That enforces policy at the syscall level, not the prompt level.
grith exists because we accepted this conclusion three years before it became consensus. Prompt injection is unfixable. So we stopped trying to fix it and built a system that does not need it to be fixed.
The model can be compromised. The architecture cannot be talked into anything.
Footnotes
-
Greshake et al. "Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection." 2023. ↩
-
Center for Internet Security. "Securing AI Agents: Understanding and Mitigating Agentic AI Threats." February 2025. ↩
-
Pasquini et al. "Neural Exec: Learning (and Learning from) Execution Triggers for Prompt Injection Attacks." Google DeepMind, 2024. ↩ ↩2 ↩3
Like this post? Share it.